

Written by Justin, October
5th, 2015
There are cases where you can write code to kick off the whole process (such as what I did with Bin Ladin’s Bookshelf) but there are other times that you are going to want to spend some time figuring out where to target your automation. This requires a bit of critical reading, and an eye for extracting relevant pieces of information. Let’s use these indictment papers and do some quick Twitter investigating to see if we can locate other interesting people potentially associated to the folks that are locked up.
Reading
Yeah. It’s weird right? Reading. I mean critically reading. It is not something that people spend a lot of time honing as a skill. It is extremely important (I know those of you who are analysts or journalists are scoffing at me right now) that you are looking at every name, location, make and model, anything that can be used as a selector. Think of each of these little disparate pieces of information as things that you are going to be using as a Google search term, a bounding box in a geographic search, or a hashtag that you’ll hunt for on Twitter.I am a bit old school when it comes to this process, so I literally will print out a document (in this case all 28 glorious pages) and grab the nearest highlighter.

- The name of the gang.
- A geographic bounding box that describes the area the gang operated in.
- A hashtag (of all things) that the gang has used in markings around the neighbourhood.
Hashtag Searches
Well the first thing we can do with Twitter is of course a hashtag search. Go ahead and click here to try it. Immediately you’ll have some hits come up: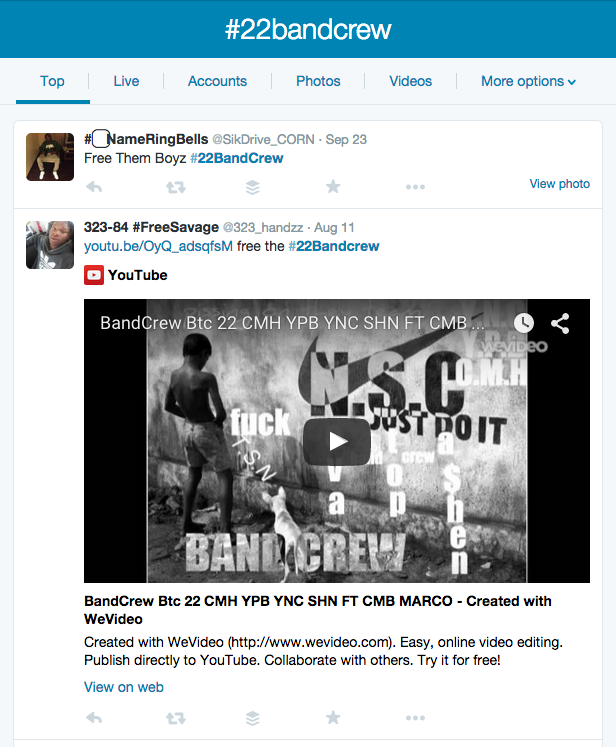
Using Lists
Even before you start writing some new code, or running some of your existing code, it is useful to use Twitter lists. Lists give you a nice way to follow accounts without having that account know that you’re following them.- Navigate to https://twitter.com/<yourusername>/lists
- Click on Create New List.
- Fill out the details for your list and make sure to mark it Private. Failing to get this step right will mean that the target account WILL know that you have added them to a list. They may not be happy if you named this list in an, ahem, colorful way.
- Now when you’re on a target profile, click the little gear icon beside the Follow button and you’ll see the option to add them to a list:
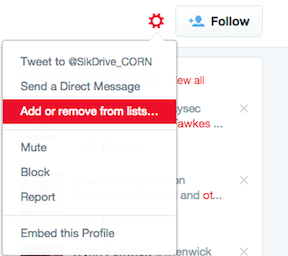
Voila! Now this account will be part of your list, which can be a nice easy way to keep an eye on accounts of interest, and to accumulate, well a list of accounts that you later want to monitor through automation.
 Geotagged Tweets
Geotagged Tweets
That perfect bounding box we saw in the first paragraph is awesome. The
OSINT gods were shining down on us for that one, as in a lot of cases there may
only be a single location named and you might have to do some legwork to figure
out a rough radius of where a group or individual actor may have operated. Not
true here. So let’s just review what they say in the indictment: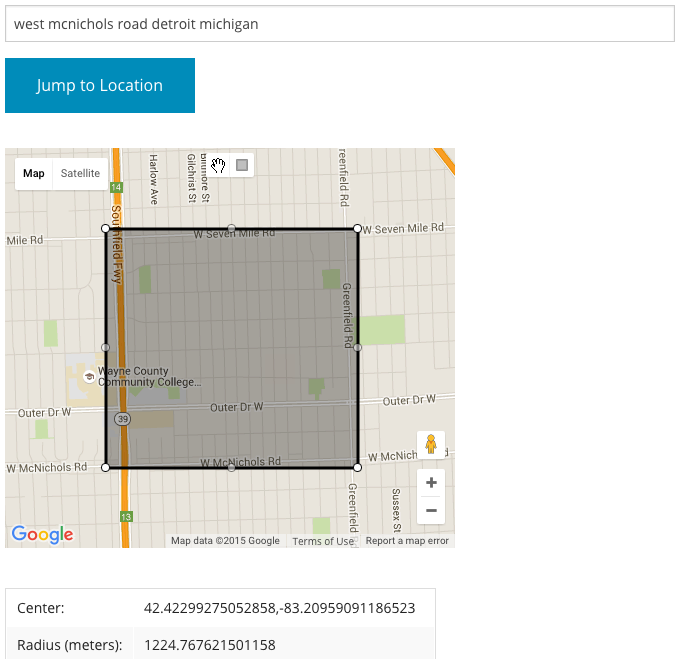
{kind=link}
… Seven Mile Road, with Southfield Freeway to the west, West McNichols Road to the south, Eight Mile Road to the north and Greenfield Road to the east.
Ok perfect. You can use my bounding box tool here to actually work this out like so:
That’s a pretty good chunk of territory! Now if you are using the Twitter API to poll for geotagged Tweets in this area you are going to use the center point and the radius. If you are planning on doing longterm monitoring then you will use the bounding box coordinates (shown lower on the page). By swiping one of my student’s Twitter code (our little secret) I had a quick and dirty Google Fusion Table complete with map in about 30 seconds:
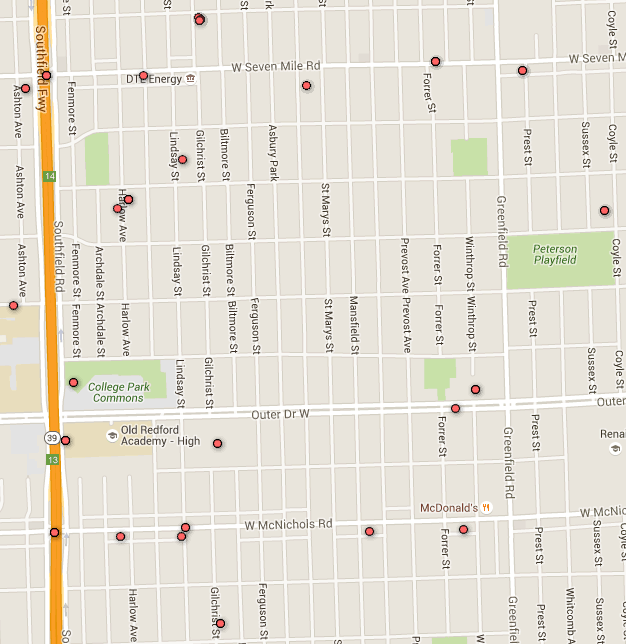
Cool, now we could explore each of these geotagged Tweets to look for more interesting people, or perhaps attempt to locate Tweets near any locations of interest from the indictment papers. You could also use a tool like cree.py here to do some of the same.
Investigating in Graphs
As you go through this exercise you should definitely be thinking in terms of graphs. How each account, location, search term, and individual are connected. This is why tools like Maltego are so powerful. This is also why the old school method was pushpins and bits of string. We operate amazingly well with graphs, and you should always be thinking about what the graph looks like for your investigation. If something doesn’t fit in your graph, that doesn’t necessarily mean discard it, there just might not be a place for it. This is also where automation becomes extremely powerful as you can cast a wide (yet targeted) net that examines relationships, common phrase usage, language and location to generate these graphs (both literally and figuratively) for you.Wrapping Up
So we have done some cursory searches and used a small subset of techniques to begin to build a better understand of the story behind the story. If you are someone who studies street gangs, or a member of law enforcement, you could very easily take a different set of indictment papers in a completely different part of the world and look at how you could augment your own research.Bonus: Extracting Text Trapped in Scanned PDFs
It is common when initial court documents are filed that you can find scanned copies of the documents trapped in images or PDF files. This is exactly the case we are dealing with here. The first thing we need to do is get the PDF converted into an image format that we can then run optical character recognition (OCR) software on to extract the text. The tool that a lot of people use is tesseract which I have found yields very good results. Your mileage may vary depending on the quality of the scan that you have. I use Ubuntu for these types of OSINT tasks, so for me (on Ubuntu 14.04):|
1
|
# sudo apt-get install imagemagick
libtesseract3 libtesseract-dev tesseract-ocr
|
|
1
2
|
# wget
"https://cbsdetroit.files.wordpress.com/2015/09/gang-file-9-22-15.pdf"
# convert -density 300
gang-file-9-22-15.pdf -depth 8 gangs.tiff
|
This will go through the process of converting the PDF to a TIFF file which we can then use tesseract to perform the OCR like so:
|
1
|
# tesseract gangs.tiff output
|
read more:
http://www.automatingosint.com/blog/2015/10/osint-gangs-of-detroit/